Contenido
En este curso de nivel básico, te vamos a contar que es el machine learning. Además veremos qué tipos de problemas de aprendizaje automático podemos encontrar y cómo se solucionan. Y siempre usando ejemplos ilustrativos que nos ayuden a entender los conceptos que se van explicando.
Recomendaciones antes de empezar
Antes de comenzar este curso básico deberás tener en cuenta unas recomendaciones. El presente curso supone que tienes unos conocimientos de programación medios en el lenguaje Python
¿Qué es el machine learning o ml?
El aprendizaje automático o en inglés machine learning (ml para acortar) es una disciplina del grupo de materias TIC. Esta disciplina se encarga de resolver problemas en los que un algoritmo informático tradicional tendría muchos problemas para obtener buenos resultados.
Un ejemplo sencillo
Para ilustrar lo que estamos explicando vamos a usar un ejemplo sencillo. Imaginemos que queremos desarrollar un sistema informático que sea capaz de determinar si un email es spam o no. Para realizar esto, podemos intentar desarrollar un programa tradicional que intente buscar palabras que habitualmente aparecen en correos fraudulentos. Podríamos realizar estudios de frecuencias de aparición de palabras, símbolos, etc.
En cualquier caso, no parece que pudiéramos desarrollar un programa sencillo para llevar a cabo esta tarea. Además, es muy fácil que nuestro software encontrara situaciones en las que fallara debido a que estamos usando una palabra habitual en un correo legítimo.
Otro problema a tener en cuenta sería la actualización de nuestro programa. Es fácil entender que la complejidad del programa haría difícil añadir nuevas palabras o estructuras para actualizar el mismo a nuevos ejemplos de spam.
Este tipo de problemas más complejos no se solucionan ya mediante software desarrollado para cada situación. Por contra, se usan técnicas de inteligencia artificial y machine learning para su resolución.
Algunos conceptos del machine learning que debemos aprender
Antes de continuar vamos a definir una serie de conceptos básicos del aprendizaje automático. Cuando pensemos en un problema de machine learning, debemos ilustrarlo como un ordenador que está aprendiendo a realizar una tarea. Esta tarea, puede ser decidir si un correo es legítimo o no, predecir el valor de una vivienda en una zona de una ciudad, etc.
Para aprender a realizar la tarea en cuestión, vamos a necesitar un conjunto de ejemplos ya realizados. Es decir, si queremos aprender a clasificar correos electrónicos tendremos un conjunto de correos ya clasificados. A esto lo denominaremos conjunto de datos o dataset.
Cada conjunto de datos estará formado por un número de ejemplos. A cada ejemplo del conjunto de datos lo llamaremos instancia. Es decir, en nuestro conjunto de datos de emails, cada email será una instancia del mismo.
Cada instancia tendrá una serie de valores que la definen a los que nosotros llamaremos atributos. Es decir, cada instancia del conjunto de datos de viviendas, tendrá definido una serie de atributos como por ejemplo: calle, zona, metros cuadrados, etc.
¿Qué tipos de problemas son los más habituales en ml?
Dentro del mundo del aprendizaje automático existen una serie de problema típicos que nos vamos a encontrar de forma recurrente. A continuación vamos a ir explicándolos con algunos ejemplos.
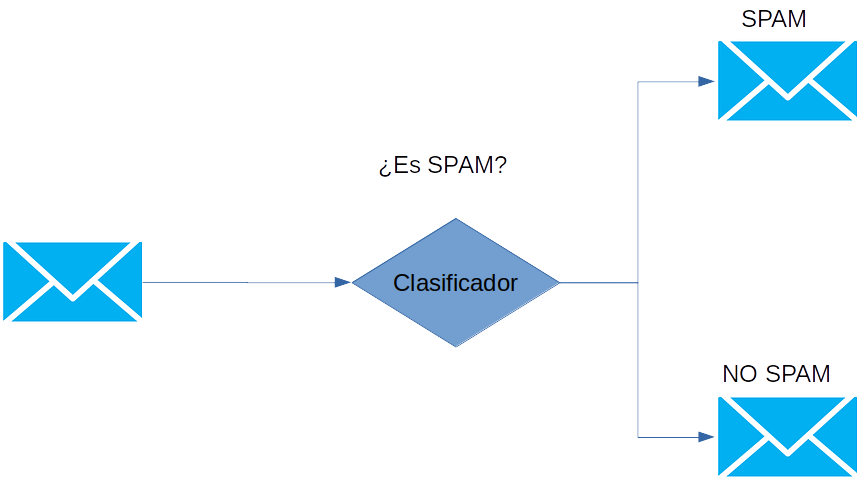
Clasificación: Este es el problema típico de aprendizaje automático. Como hemos definido anteriormente en este tipo de problemas vamos a clasificar algo en base a unos valores. Por ejemplo, supongamos que queremos clasificar un email como spam o correo legítimo en base a su contenido. Tendríamos un problema de clasificación como el que aparece en la siguiente imagen.
Regresión: Este tipo de problemas es muy habitual en machine learning. Consiste en la predicción de un valor numérico en base a una serie de valores. Por ejemplo, imaginemos que queremos predecir el coste de una pizza en función del atributo del tamaño del radio de la misma en centímetros. Así tendríamos un problema de regresión que consistiría en obtener una función similar a la que aparece en el siguiente gráfico.

Clusterización: Este tipo de problema también conocido como agrupamiento o clustering en inglés, también es habitual. Consiste en separar las instancias de nuestro dataset en grupos homogéneos en base a los valores de los atributos de cada instancia. Así, imaginemos una empresa de ventas que tenga una base de datos de clientes. Para cada cliente tendrá una serie de atributos. Este tipo de empresa quiere separar o segmentar sus clientes en grupos homogéneos para atender mejor a sus necesidades.

¿Cómo se clasifican los problemas de machine learning?
Antes hemos visto algunos ejemplos de problemas de machine learning. Estos problemas pueden ser clasificados en tres grandes grupos:
- Aprendizaje supervisado: Este tipo de aprendizaje automático es en el que tenemos un conjunto de datos y los resultados deseados de los mismos. Es decir, disponemos de un dataset y el valor objetivo está definido. Así, el valor definido podrá ser una etiqueta en los problemas de clasificación, o bien un valor numérico para problemas de regresión.
- Aprendizaje no supervisado: En contraposición con el caso anterior, aquí disponemos de un conjunto de datos que no tiene el resultado que queremos obtener. Es decir, tendremos un dataset con instancias y sus atributos, pero no dispondremos de ninguna etiqueta ni valor que queramos obtener. Por contra, lo que se pretende en este tipo de problemas es que el algoritmo de machine learning, descubra de forma autónoma grupo de instancias homogéneas, patrones en los datos, etc. Un caso típico de este tipo de problemas es el agrupamiento, clusterización clustering en inglés.
- Aprendizaje semi-supervisado: Este será un caso mixto con respecto a los dos anteriores. Así, el conjunto de datos de este tipo de problemas estará formado por un pequeño grupo de datos etiquetados y el resto no etiquetados. Es decir, nuestro dataset tendrá un pequeño número de instancias con un valor objetivo (etiqueta o valor numérico), y un gran conjunto de instancias sin valor objetivo. Esto sucede con los algoritmos de agrupamiento que se usan para datasets con datos faltantes. Por ejemplo podemos ver esto en el algoritmo de esperanza-maximización.
Artículos del curso
Para continuar con el curso básico vamos a utilizar los siguientes artículos. Puede leer los artículos en el orden que le proponemos o en el orden que más te interese, ya que, ya hemos explicado los conceptos básicos para poder entenderlos.

Aprendizaje automático con Scikit-learn #1: Clasificación

Aprendizaje automático con Scikit-learn (Parte #2): Regresión lineal

Aprendizaje automático con Scikit-learn (Parte #3): Clusterización

Preprocesamiento de datasets con Python, Scikit-learn y Pandas (Parte #4)
Sugerencias